پایگاههای داده رابطه ای به دلیل نوع ساختار خود، برای تحلیل دادههای بزرگ غیر بهینه، ناکارا و همینطور کند بودند. البته در بعضی موارد هم استفاده از ساختار جدولی که در پایگاههای داده رابطه ای استفاده میشود تقریبا ناممکن بود. به همین دلیل ذخیره سازی حجم زیادی از دادههای بی ساختار (Non-structured Data) سرعت و کارایی این پایگاههای داده را به شدت کاهش میداد. تا اینکه پایگاههای داده NoSQL پا به عرصه گذاشتند. پس همانطور که حدس میزنید، هدف اصلی ایجاد پایگاههای داده NoSQL کار با دادههای بی ساختار و حجیم است.
در برنامه نویسی سنتی، پایگاههای داده معمولا از نوع SQL هستند؛ که یک پایگاه داده رابطه ای یا Relational است. پایگاههای داده رابطه ای ساده هستند و کار کردن با آنها معمولا بی دردسر و راحت است. اما این نوع از پایگاههای داده یک مشکل بزرگ دارند. این مشکل زمانی خود را نشان داد که غولهای نرم افزاری دنیا مثل گوگل، آمازون و فیسبوک احتیاج به تحلیلِ دادههای با حجم و تعداد بالا یا همان Big Data پیدا کردند.
آشنایی با ساختار پایگاه داده SQL
اگر تجربه استفاده از SQL را داشته باشید میدانید که در استفاده از آن همیشه باید تابع قوانین باشید. یعنی باید مجموعه ای از اطلاعات یکسان با مشخصات یکسان را در جداول (Table) مربوط به خود جاگذاری نمایید. در واقع باید بگوییم که در SQL باید برای این سوال ها، به ازای هر داده پاسخ مشخصی داشته باشید:
- چه موجودیت (Entity) هایی دارید؟ اطلاعات قرار است در قالب چه دسته هایی ذخیره سازی شود؟ مثل دستههای کاربر، خبر، کامنت و… همگی نمونه هایی از موجودیت هستند. معمولا هر موجودیت در قالب یک جدول در نظر گرفته میشود.
- هر جدول شما چه خاصیت هایی دارد؟ چه اطلاعات مشخصی را قصد دارید در آن ذخیره کنید؟ به یاد داشته باشید که این خواص باید ثابت باشند! چرا که هر کدام از این خواص به معنی یک ستون (Column) از جدول شما هستند. مثلا جدول کاربر میتواند شامل ستونهای نام، نام خانوادگی، سن، پست الکترونیک و… باشد و قرار نیست این تعداد ستونها برای هر کاربر متفاوت باشد.
- هر داده شما چه اطلاعاتی دارد؟ هر داده جدید در قالب یک سطر (Row) جدید در جدول مورد نظرتان ذخیره میشود. به طور مثال به ازای هر کاربر جدید یک سطر با ستونهای نام، نام خانوادگی، سن و… در جدول کاربران تشکیل میشود.
- هر جدول شما چه ارتباطی (Relation) با جدول یا جداول دیگر دارد؟ مثلا هر کاربر میتواند عضوی از یک یا چند کلاس درس و هر کلاس درس میتواند شامل مجموعه ای از کاربران باشد.

Schema
تمام این مشخصات پایگاه داده شما در SQL با ساختاری به نام Schema (بخوانید اسکیما) ذخیره میشود. Schema یک ساختار ثابت است و مانند اسکلت یک ساختمان عمل میکند. همه چیز روی آن سوار و بر پایه آن تکمیل میشود. شاید تا الان فهمیده باشید که مشکل اصلی این نوع از پایگاه داده در ذخیره سازی دادههای بی ساختار کجاست! در ذخیره سازی این گونه داده ها، خصوصیات هر داده همواره ثابت نیست و این باعث ناکارایی و بعضا غیر قابل استفاده شدن SQL برای آنها میشود.
پایگاههای داده NoSQL
پایگاههای داده (Not Only SQL) NoSQL برعکس نوع SQL از ساختارهای Schema غیر ثابت یا Dynamic Schema استفاده میکنند. این باعث میشود که برنامه نویسان احتیاجی به تشکیل ساختارهای سخت گیرانه مشخص، پیش از ایجاد پایگاههای داده را نداشته باشند. این پایگاههای داده میتوانند انواع مختلفی داشته باشند و برعکس SQL برای ذخیره سازی دادهها از XML یا JSON استفاده میکنند.
در ادامه انواع مختلفی از پایگاههای داده NoSQL را به شما معرفی میکنیم:
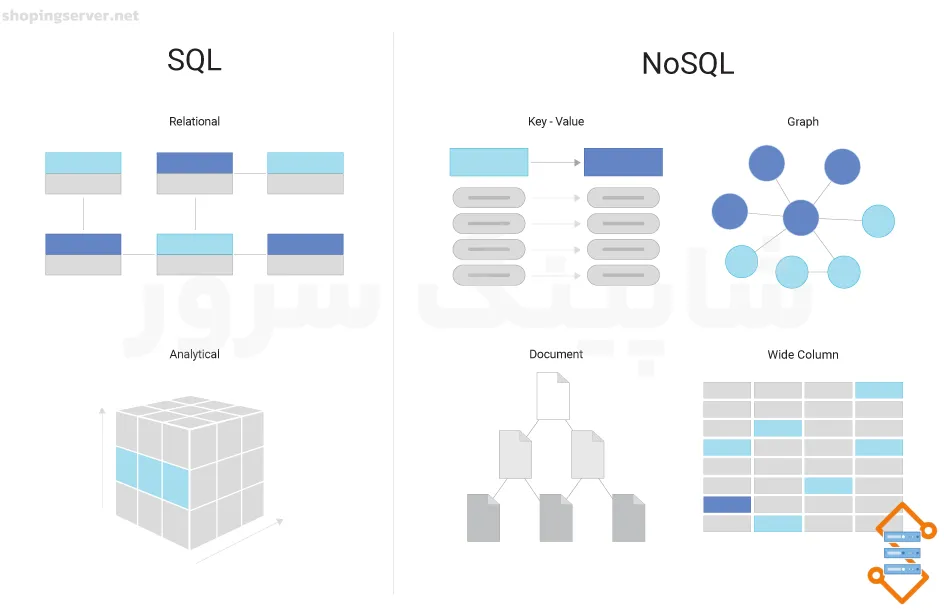
- پایگاههای داده کلید-مقدار یا Key-Value Database: در این نوع از پایگاه داده اطلاعات در قالب جفتهای کلید-مقدار یا Key-Value ذخیره میشود. کلیدها نقش شناسه هر داده را بازی میکند. یعنی میتوانیم با استفاده از آنها مقادیر مختلف داده را ذخیره یا پیدا کنیم. پایگاههای داده کلید-مقدار به دلیل ساده بودن در کارکرد، پرکاربردترین نوع پایگاههای داده NoSQL هستند.
- پایگاههای داده ستونی یا Wide-Column Database: شاید تصور کنید پایگاههای داده ستونی همان پایگاههای داده رابطه ای هستند. اما این فقط ظاهر این گونه پایگاههای داده است که شبیه به نوع رابطه ای است. گفتیم که در پایگاههای داده رابطه ای لازم است که تعداد و نوع ویژگیهای هر موجودیت و مقادیر داخل آن مشخص و ثابت باشد. این در حالی است که در پایگاههای داده ستونی، هر ستون در رکوردهای مختلف میتواند شامل داده هایی با ساختار و نوع متفاوت باشد.
- پایگاههای داده سندی یا Document Database: در این گونه پایگاههای داده برای ذخیره سازی دادهها از اسناد JSON یا XML استفاده میکنیم. پایگاههای داده سندی معمولا برای ذخیره سازی و استفاده از دادههای پراکنده و بی ساختار استفاده میشوند.
- پایگاههای داده گرافی یا Graph Database: در این نوع از پایگاههای داده برای ذخیره سازی موجودیتها و روابط بین آنها از گراف استفاده میکنیم. پایگاههای داده گرافی برای مواردی که در آنها به ایجاد ارتباطهای متعدد بین جداول احتیاج داریم بسیار مناسب هستند.
- پایگاههای داده چند مدله یا Multimodel Database: پایگاههای داده چند مدله ترکیبی از انواع دیگر پایگاه داده هستند. در این نوع پایگاههای داده میتوانیم دادهها را به روشهای مختلفی ذخیره، و از آنها استفاده کنیم.
مزیتهای استفاده از NoSQL
پایگاههای داده NoSQL مزیتهای بسیار زیادی دارند که آنها را برای سیستمهای بزرگ و توزیع شده تبدیل به بهترین گزینه میکند. به طور کلی میتوان این مزیتها را به این شکل خلاصه کرد:
- مقیاس پذیری بالا (Scalability): پایگاههای داده NoSQL میتوانند به راحتی با روش مقیاس پذیری افقی یا Horizontal Scaling گسترش پیدا کنند. این ویژگی باعث کم شدن پیچیدگی و هزینه مقیاس دادن به نرم افزار یا Scale کردن آن میشود.
- کارایی بالا (Performance): در سیستمهای توزیع شده NoSQL با تکثیر خودکار دادههای NoSQL در سرورهای متعدد در سراسر دنیا، تاخیر در ارسال پاسخ از طرف سرور به پایینترین حد ممکن میرسد.
- دسترسی بالا (Availability): در سیستمهای توزیع شده NoSQL به دلیل کپی شدن خودکار دادهها در سرورهای مختلف، با از دسترس خارج شدن یک یا چند سرور، پایگاه داده همچنان قابل دسترس و پاسخگو است.
نتیجه گیری
دیدیم که پایگاههای داده رابطه ای و مبتنی بر SQL گرچه از مزیت ساختار یافتگی و قانونمندی برخوردارند، اما برای سیستمهای بی ساختار یا تحلیل دادههای بزرگ مناسب نیستند. این به آن معنی است که مزیت آنها در بسیاری از سیستمهای بزرگ مثل موتورهای جستجو، تبدیل به بزرگترین نقطه ضعف میشود. برای حل این مشکل، پایگاههای داده NoSQL مثل MongoDB، پابه عرصه گذاشتند. پایگاههای داده NoSQL به راحتی در سیستمهای توزیع شده مورد استفاده قرار میگیرند، و باعث بهبود عملکرد آنها میشوند.