
پایتون یکی از زبانهای برنامهنویسی محبوب در حوزه هوش مصنوعی (AI) است. این زبان به عنوان یک ابزار قدرتمند برای توسعه الگوریتمهای هوش مصنوعی و یادگیری ماشین استفاده میشود. پایتون با داشتن کتابخانههایی مانند Scikit-learn، TensorFlow و PyTorch به عنوان یکی از زبانهای برنامهنویسی محبوب برای توسعه الگوریتمهای یادگیری ماشین شناخته شده است. با استفاده از این کتابخانهها، میتوانید مدلهای مختلف یادگیری ماشین را پیادهسازی کنید و آنها را برای تشخیص الگوها، پیشبینیها و یا سایر کاربردهای مرتبط با دادهها بکار ببرید. همچنین، پایتون با داشتن محیطهای توسعه مختلفی مانند Jupyter Notebook، PyCharm و Sublime Text، به برنامهنویسان کمک میکند که به راحتی کد نویسی کرده و به تست و اجرای آنها بپردازند.
در کل، پایتون با توجه به سادگی و قابلیت فهم آسان و همچنین دارا بودن کتابخانههای گسترده و مفید، برای یادگیری ماشین و هوش مصنوعی یکی از بهترین زبانهای برنامهنویسی است. در ادامه به برخی از کاربردهای پایتون در تکنولوژی هوش مصنوعی اشاره میکنیم.
یادگیری ماشین (Machine Learning)
یادگیری ماشین یکی از حوزههای مهم هوش مصنوعی است که به کامپیوترها اجازه میدهد تا از دادهها به صورت خودکار یاد بگیرند و برای حل مسائل استفاده شوند. در واقع، هدف اصلی یادگیری ماشین، یافتن الگوهای موجود در دادهها و ساخت مدلهایی است که بتوانند این الگوها را تشخیص دهند و برای پیشبینی نتایج جدید استفاده شوند.
اصولا، یادگیری ماشین به طور کلی به دو دسته تقسیم میشود: یادگیری نظارت شده و یادگیری بدون نظارت. در یادگیری نظارت شده، مدل با استفاده از دادههای ورودی و خروجی مربوط به آنها آموزش داده میشود. به این ترتیب، پس از آموزش، این مدل میتواند برای ورودیهای جدید، خروجی مناسب تولید کند. در یادگیری بدون نظارت، هدف یادگیری این است که مدل بتواند الگوهای موجود در دادههای ورودی را بدون نیاز به دادههای خروجی یاد بگیرد.
یادگیری ماشین در حوزههای مختلفی از جمله تشخیص چهره، ترجمه ماشینی، تشخیص صدا، پردازش زبان طبیعی، پیشبینی قیمت سهام، تحلیل دادههای پزشکی و غیره مورد استفاده قرار میگیرد.
بسیاری از کتابخانههای مفید در پایتون برای یادگیری ماشین و هوش مصنوعی وجود دارند. در ادامه به معرفی برخی از این کتابخانه ها می پردازیم.
NumPy
این کتابخانه برای عملیات علمی و محاسباتی در پایتون استفاده میشود، به طور خاص برای عملیات آرایهای، الگوریتمهای خطی، و محاسبات آماری. این کتابخانه بسیار سریع و بهینه است و میتواند برای پردازش دادههای بزرگ بسیار مفید باشد. یکی از کاربردهای این کتابخانه در یادگیری ماشین، پردازش دادههای تصویری است. به عنوان مثال، با استفاده از NumPy میتوانید تصاویر را به صورت آرایهای از اعداد درآورید و سپس آنها را به عنوان ورودی به الگوریتمهای یادگیری ماشینی مثل شبکههای عصبی بدهید.
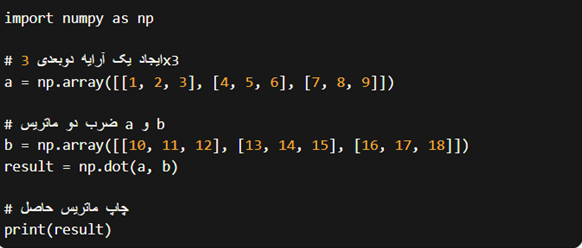
در ادامه نمونه کدی از NumPy برای ایجاد آرایه و اعمال عملیات ماتریسی آن را مشاهده میکنید:
Pandas
از این کتابخانه برای کار با دادههای ساختار یافته مانند دادههای جداولی و فایلهای CSV و Excel استفاده می کنیم. این کتابخانه میتواند برای پردازش دادههای بزرگ و پیچیده بسیار مفید باشد و ابزارهای بسیاری برای انتخاب و تحلیل دادهها در اختیار شما قرار میدهد. یکی از کاربردهای Pandas در یادگیری ماشین، پردازش دادههای مربوط به مجموعه دادهها است. به عنوان مثال، با استفاده از Pandas میتوانید دادههای مربوط به مجموعه دادهها را بارگیری کنید و آنها را به عنوان ورودی به الگوریتمهای یادگیری ماشینی مثل رگرسیون خطی و درخت تصمیمگیری بدهید.
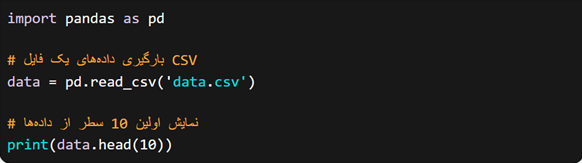
در ادامه نمونه کدی از Pandas برای بارگیری دادههای CSV و نمایش آنها را مشاهده میکنید:
Matplotlib
میتوان از این کتابخانه برای رسم نمودارها و تجسم دادهها استفاده کرد. همچنین، این کتابخانه میتواند برای نمایش دادههای پیچیده و تحلیل نتایج به دست آمده از الگوریتمهای یادگیری ماشینی بسیار مفید باشد. یکی از کاربردهای Matplotlib در یادگیری ماشین، تجسم دادههای مربوط به دستهبندی است. به عنوان مثال، با استفاده از Matplotlib میتوانید دادههای مربوط به دو یا چند دسته را با استفاده از نمودارهای مختلف نمایش دهید و برای بررسی عملکرد الگوریتمهای دستهبندی مختلف از آنها استفاده کنید.
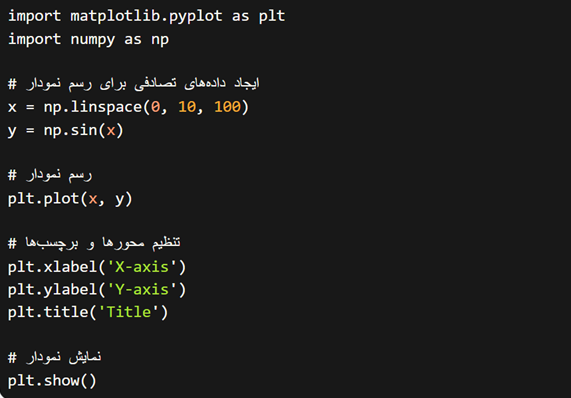
نمونه کدی از Matplotlib برای رسم یک نمودار خطی را در زیر مشاهده میکنید:
Scikit-learn
این کتابخانه پایتونی محبوب برای تحلیل دادههای بزرگ و یادگیری ماشین به کار می رود. Scikit-learn دارای الگوریتمهای مختلفی برای یادگیری ماشین، دستهبندی، خوشهبندی، رگرسیون و … است. همچنین، این کتابخانه دارای ابزارهای بسیاری برای پیشپردازش دادهها، تجزیه و تحلیل دادهها و ارزیابی مدلهای یادگیری ماشین است.
در ادامه یک نمونه کد برای آموزش یک مدل خطی با Scikit-learn را قرار داده ایم:

این نمونه کد یک مدل خطی را با استفاده از کتابخانه Scikit-learn آموزش میدهد و سپس از مدل برای پیشبینی خروجی برای ورودیهای جدید استفاده میکند.
مثالی از پیادهسازی الگوریتمهای یادگیری ماشین در پایتون
به عنوان مثال، الگوریتم “Random Forest” یک الگوریتم یادگیری ماشین محبوب است که در مورد مسائل پیشبینی و طبقهبندی استفاده میشود. این الگوریتم، یک مجموعه از شاخه های تصمیمگیری را به صورت تصادفی ایجاد میکند و سپس با استفاده از این شاخه ها، پیشبینیهایی را انجام میدهد.
برای پیادهسازی الگوریتم “Random Forest” در پایتون، میتوان از کتابخانه scikit-learn استفاده کرد. در ادامه، یک مثال ساده از پیادهسازی این الگوریتم در پایتون آورده شده است:
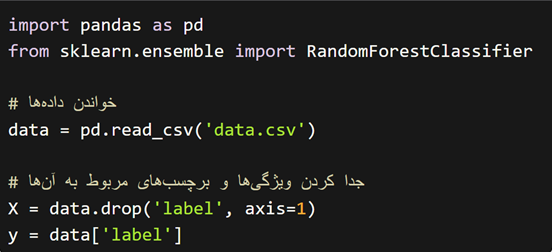
ابتدا، کتابخانههای مورد نیاز را import کرده و دادههای خود را بارگیری میکنیم.
سپس، دادههای خود را به دو بخش “آموزش” و “آزمون” تقسیم میکنیم.
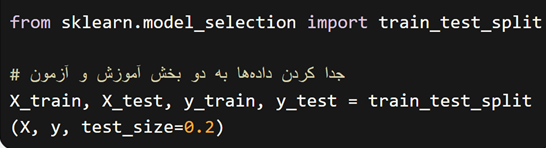
بعد از آن، یک شی از کلاس “RandomForestClassifier” میسازیم و آن را با دادههای آموزشی، آموزش میدهیم.
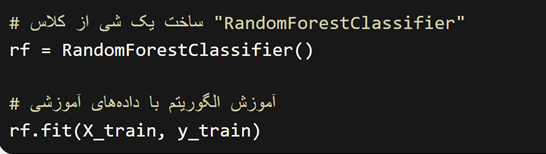
و نهایتا، با استفاده از دادههای آزمون، پیشبینیهای الگوریتم را بررسی میکنیم.
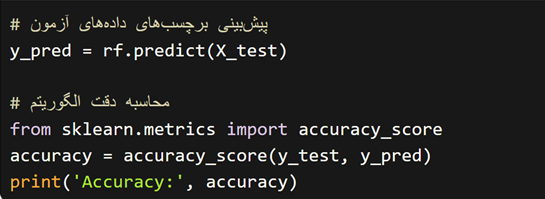
در این مثال، با استفاده از الگوریتم “Random Forest”، میتوانیم برچسبهای دادههای جدید را پیشبینی کنیم.
TensorFlow
این یک کتابخانه محبوب برای یادگیری ماشین و شبکههای عصبی در پایتون است. TensorFlow میتواند برای طراحی، آموزش و اجرای شبکههای عصبی مورد استفاده قرار گیرد. همچنین این کتابخانه در تحلیل دادههای بزرگ و پیچیده، پردازش تصویر و پردازش زبان طبیعی مفید است. TensorFlow دارای ابزارهای بسیاری برای مدیریت داده، نمایش دادهها و تحلیل نتایج است.
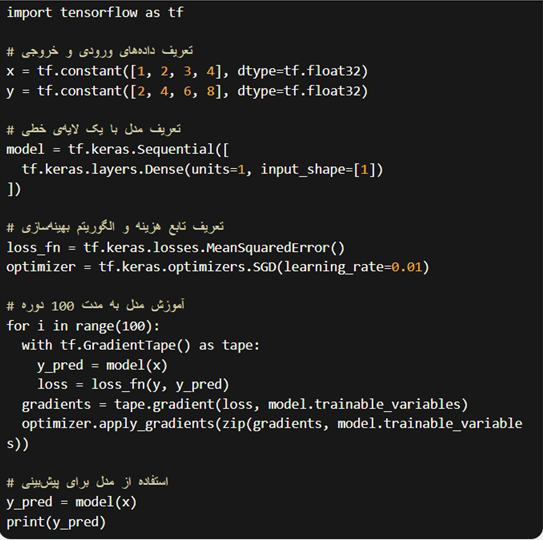
در ادامه یک نمونه کد برای ساخت یک شبکهی عصبی ساده با TensorFlow قرار داده ایم:
PyTorch
این کتابخانه نسبتاً جدیدتری است که برای تحلیل دادههای بزرگ و یادگیری ماشین در پایتون استفاده میشود. PyTorch دارای ابزارهایی برای طراحی، آموزش و اجرای شبکههای عصبی است. همچنین، این کتابخانه توسعه دهندگان را قادر میسازد تا به راحتی شبکههای عصبی پیچیدهتری را طراحی و پیادهسازی کنند.
برای مثال، میتوانید با استفاده از کد زیر یک شبکهی عصبی ساده با PyTorch بسازید.
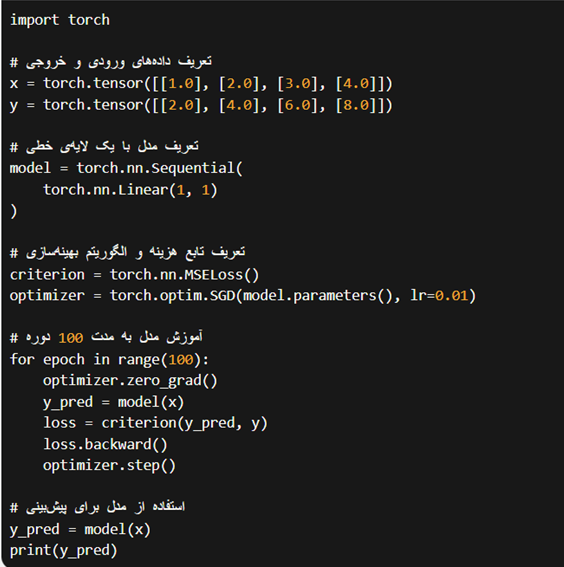
Keras
کتابخانه Keras یکی دیگر از کتابخانههای محبوب برای یادگیری ماشین و شبکههای عصبی در پایتون است. این کتابخانه برای تسریع فرآیند توسعه شبکههای عصبی طراحی شده است و محبوبیت زیادی در حوزه تحقیقات و صنعت دارد. یکی از ویژگیهای خوب Keras این است که اجازه میدهد تا به سادگی شبکههای عصبی چندلایه با معماریهای مختلف ساخته شود. همچنین، این کتابخانه دارای ابزارهای بسیاری برای پیاده سازی شبکههای عصبی، شبکههای کانولوشنال و شبکههای بازگشتی است.
در ادامه، یک نمونه کد برای ساخت یک شبکهی عصبی ساده با Keras قرار داده ایم.
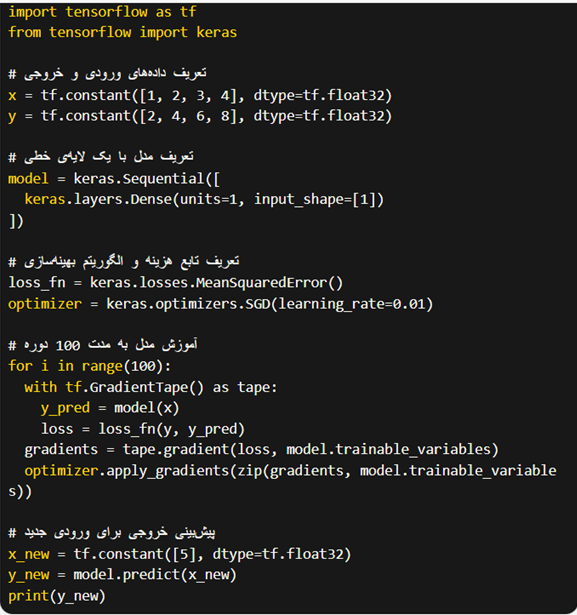
این کد، برای ساختن یک شبکهی عصبی با یک لایهی خطی استفاده میشود. در هر دوره، مقدار هزینه با استفاده از تابع هزینه Mean Squared Error محاسبه شده و با استفاده از الگوریتم بهینهسازی SGD به روزرسانی شده است. در نهایت، با استفاده از predict، خروجی برای ورودی جدید محاسبه شده و چاپ میشود.
با توجه به مثال بالا، میتوانید با Keras شبکههای عصبی ساده تا پیچیدهتری را بسازید و آنها را برای پیشبینی، دستهبندی و یا تشخیص اشیاء بکار ببرید.
OpenCV
یک مثال از کاربرد پایتون در هوش مصنوعی، پیادهسازی یک الگوریتم یادگیری ماشین برای تشخیص چهره است. با استفاده از کتابخانه OpenCV و یک شبکه عصبی پیچیده، میتوانید یک الگوریتم تشخیص چهره پیادهسازی کنید. برای این منظور باید مراحل زیر را انجام دهید.
ابتدا نصب کتابخانه OpenCV و TensorFlow

سپس، بارگیری یک مجموعه داده چهره مثل مجموعه داده Labeled Faces in the Wild (LFW) ، که برای این کار میتوانید از این سایت استفاده کنید:
بعد از آن باید پردازش تصاویر و ساخت دادههای آموزشی و آزمایشی را انجام دهید. سپس، دادههای آموزشی و آزمایشی را به دو بخش تقسیم کنید.
پس از آن یک شبکه عصبی برای تشخیص چهره بسازید. میتوانید از یک شبکه عصبی کانولوشنال با معماری مشابه شبکه عصبی VGG-16 استفاده کنید.
در مرحله بعدی آموزش شبکه عصبی با استفاده از دادههای آموزشی را انجام دهید. در این مرحله، شبکه عصبی با استفاده از الگوریتم Backpropagation و الگوریتم بهینهسازی Adam بهروزرسانی میشود.
مراحل پایانی شامل ارزیابی دقت شبکه عصبی با استفاده از دادههای آزمایشی و استفاده از شبکه عصبی برای تشخیص چهره در تصاویر و ویدیوها هستند.
یک نمونه کد برای پیادهسازی یک الگوریتم تشخیص چهره با استفاده از OpenCV و شبکه عصبی ساده در TensorFlow را در زیر می بینید:
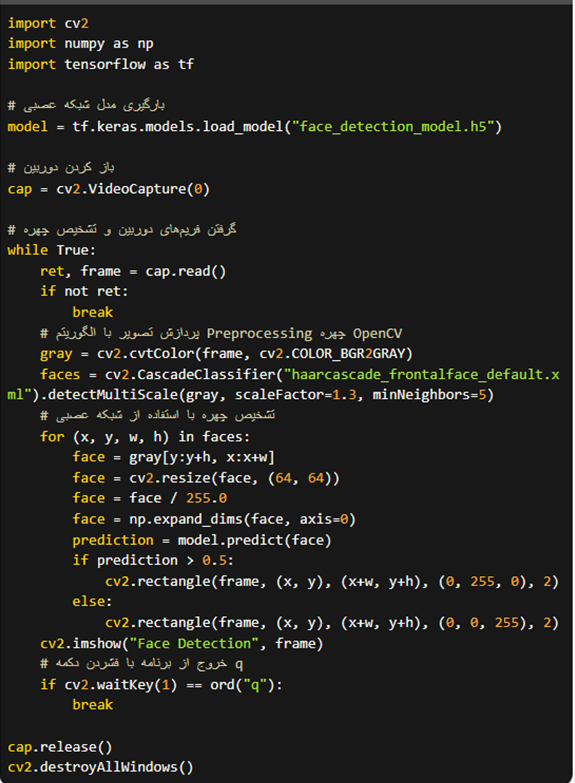
در این کد، یک شبکه عصبی ساده با یک لایه کانولوشنال و یک لایه کاملا متصل برای تشخیص چهره استفاده شده است. مدل شبکه عصبی در فایل face_detection_model.h5 ذخیره شده است. برای تشخیص چهره، ابتدا تصویر گرفته شده از دوربین با الگوریتم Preprocessing چهره OpenCV پردازش شده و سپس به شبکه عصبی داده میشود. شبکه عصبی پس از پردازش تصویر، برای هر چهره یک پیشبینی از صحت تشخیص چهره ارائه میدهد. سپس، با استفاده از رنگ قرمز و سبز، بر روی تصویر اعلام میشود که چهره تشخیص داده شده است یا خیر.
کلام آخر
در این مقاله به کاربرد پایتون در هوش مصنوعی در بخش یادگیری ماشین پرداخته ایم و کتابخانه های معروفی که در این زمینه وجود دارند را معرفی کرده ایم از شما ممنونیم که تا پایان مقاله همراه ما بوده اید.










